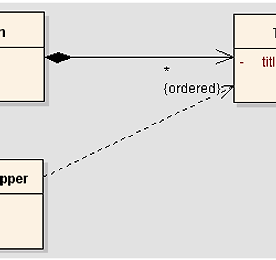
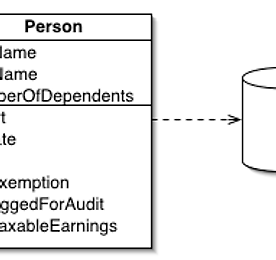
소프트웨어아키텍처 썸네일형 리스트형 [SA강좌] Part 4-19 Embedded Value 패턴 내재된 값(Embedded Value) 패턴 내재된 값 패턴의 정의 내재된 값 패턴은 개체를 다른 개체의 테이블의 몇몇 필드들에 매핑한다. 그림 Ⅴ-26. 내재된 값 패턴의 구조 내재된 값 패턴의 설명 많은 작은 개체들은 테이터베이스의 테이블들 처럼 의미적이지 않은 개체지향 시스템 안에서 의미있게 한다. 예로 동시 발생 인식 메모리 개체와 일자 범위를 포함한다. 비록 기본적 생각은 개체를 테이블과 같이 저장하고, 같지 않은 사원은 메모리 값을 테이블이 원한다. 내재된 값은 개체의 값을 개체 소유자의 레코드에 있는 필드에 매핑한다. 내재된 값 패턴의 예제: 값 개체 내포된 값과 매핑되는 값 개체의 예는 아래와 같다. 다음과 같은 필드들을 가진 간단한 요청 클래스로 시작한다. class ProductOffe.. 더보기 [SA강좌] Part 4-18 Dependent Mapping 패턴 의존 매핑(Dependent Mapping) 패턴 의존 매핑 패턴의 정의 의존 매핑 패턴은 자식 클래스를 위한 데이터베이스 매핑을 수행하는 하나의 클래스를 가진다. 그림 Ⅴ-24. 의존 매핑 패턴의 구조 의존 매핑 패턴의 설명 몇몇 개체들은 자연적으로 다른 개체의 컨텍스트에 나타난다. Album을 추적하면 album 진행시 적재되거나 저장될 때 적재되거나 저장된다. 데이터베이스에서 임의의 테이블에 의해서 참조되지 않는다면, 추적을 위한 매핑 수행을 하는 앨범 매퍼에 의해 매핑 절차를 단순화 할 수 있다. 의존 매핑은 매퍼로 처리한다. 의존 매핑 패턴은 언제 사용하는가? 다른 개체에 의해 참조되는 개체를 가지고 있으면 의존 매핑을 사용한다. 이경우 하나의 개체가 의존 집합을 가지고 있을 때 일반적으로 발생.. 더보기 [SA강좌] Part 4-17 Association Table Mapping 패턴 연관 테이블 매핑(Association Table Mapping) 패턴 연관 테이블 매핑 패턴의 정의 연관 테이블 매핑은 외래키를 갖는 테이블을 연관 관계의 테이블에 저장하는 패턴이다. 그림 Ⅴ-23. 연관 테이블 매핑 패턴의 구조 연관 테이블 매핑 패턴의 설명 개체는 다중값 필드들을 필드 값처럼 집합(collection)을 사용하여 쉽게 조작할 수 있다. 관계형 데이터베이스는 이러한 특성이 없고, 단일 필드 값에 의해서 제약된다. 일-대-일 관계를 매핑할 때는 외래키 매핑(Foreign Key Mapping)을 이용하여 처리 할 수 있다. 근본적으로 연관의 단일 값을 위한 외래키를 사용한다. 그러나, 다-대-다 관계는 이와 같이 할 수 없다. 왜냐하면 외래키를 가지는 단일 값이 없기 때문이다. 이러한 .. 더보기 [SA강좌] Part 4-16 Foreign Key Mapping 패턴 외래키 매핑(Foreign Key Mapping) 패턴 외래키 매핑 패턴의 정의 외래키 매핑 패턴은 개체들 사이의 연관성을 테이블 사이의 외래 키 참조에 매핑한다. 그림 Ⅴ-21. 외래키 매핑 패턴의 구조 외래키 매핑 패턴의 설명 개체들은 개체 참조에 의해서 직접적으로 서로를 참조한다. 심지어 매우 간단한 개체지향 시스템은 의도된 서로 연결된 개체들을 포함한다. 이들 개체들을 데이터베이스에 저장하기 위해 개체 참조를 저장하는 것은 중요하다. 그러나, 데이터는 실행 프로그램의 한정된 인스턴스로 한정되므로 행 데이터 값을 단지 저장 할 수 없다. 좀더 복잡한 것은 개체들은 다른 개체들을 참조하는 집합을 포함한다. 외래키 매핑은 개체 참조를 데이터베이스에 있는 외래키와 매핑한다. 왜래키 매핑 패턴은 언제 사용.. 더보기 [SA강좌] Part 4-15 Identity Map 패턴 일치 맵(Identity Map) 패턴 일치 맵 패턴의 정의 일치 맵 패턴은 맵에 로드된 모든 개체의 유지에 의하여 개별 개체는 한번만 로드됨을 확신한다. 이러한 개체들을 참고 할 때 맵을 사용한 개체 검색을 하는 패턴이다. 그림 Ⅴ-18. 일치 맵 패턴의 구조 일치 맵 패턴의 설명 일치 맵 패턴은 단일 비즈니스 트랜잭션에 있는 데이터베이스에서 읽은 모든 개체의 패턴을 유지 시킨다. 객체를 원하는 경우에는 이미 가지고 있다면 일치 맵 패턴을 처음에 확인한다. 일치 맵 패턴의 사용 비일치성을 막는다. 수행성을 향상시킨다. 일반적으로 일치 맵 패턴은 데이터베이스에서 가져온 개체를 관리하기 위해 사용한다. 중요한 이유는 메모리 상에 두개의 개체가 하나의 데이터베이스 레코드에 대응 되기를 원하지 않기 때문이다... 더보기 [SA강좌] Part 4-14 Unit of Work 패턴 작업 단위(Unit of Work) 패턴 작업 단위 패턴의 정의 비즈니스 트랜잭션의 영향 받은 개체의 리스트를 관리하고, 변화의 기록과 동시 발생 문제의 해결를 조정하는 패턴이다. 그림 Ⅴ-17. 작업 단위 패턴의 구조 작업 단위 패턴의 설명 데이터베이스 내부와 외부로 데이터를 가지고 오는 경우 변화를 추적하는 것은 중요하다. 즉, 데이터가 데이터베이스에 쓰이지 않은 경우 이다. 비슷하게 새로운 개체를 삽입하면 개체를 생성하고, 임의의 개체를 삭제하면 개체를 삭제해야 한다. 작업 단위 패턴은 데이터베이스에 영향 받을 수 있는 비즈니스 트랜잭션 동안 모든 작업의 추적을 유지한다. 작업의 결과와 같은 데이터베이스 변경에 필요한 모든 작업을 설명한다. 작업 단위 패턴의 사용 이유 수행성 향성 비일관성을 제거 .. 더보기 [SA강좌] Part 4-13 Data Mapper패턴 데이터 매퍼(Data Mapper) 패턴 데이터 매퍼 패턴의 정의 매퍼의 레이어는 개체와 데이터베이스 사이에 데이터를 이동시킨다. 그림 Ⅴ-16. 데이터 매퍼 패턴의 구조 데이터 매퍼 패턴의 설명 개체와 관계형 데이터베이스는 데이터를 구조화하는 메커니즘이 서로 다르다. 집합과 상속과 같은 개체의 많은 부분들이 관계형 데이터베이스에는 존재하지 않는다. 데이터 매퍼는 데이터베이스에서 메모리 위에 있는 개체를 분리하는 소프트웨어 레이어 이다. 데이터 매퍼 패턴은 언제 사용하는가? 데이터 매퍼를 위한 주요한 이슈는 데이터베이스 스키마와 독립적으로 포함된 개체 모델을 원할 때이다. 데이터 매퍼 패턴의 예제 : 간단한 데이터베이스 매퍼 class Person private String lastName; privat.. 더보기 [SA강좌] Part 4-12 Active Record 패턴 활성화 레코드(Active Record) 패턴 활성화 레코드 패턴의 정의 데이터베이스 테이블 또는 뷰에 있는 행을 포함하는 객체, 데이터베이스 접근을 포함하고, 데이터에 있는 도메인 로직을 추가한다. 그림 Ⅴ-15. 활성화 레코드 패턴의 구조 활성화 레코드 패턴의 설명 개체는 데이터와 행동 두 가지를 전달한다. 대부분의 이 데이터는 유지되고, 데이터베이스에 저장 되어 진다. 활동 레코드는 도메인 개체에 데이터 접근 로직을 추가하는 가장 분명한 접근으로 사용 된다. 이 방법은 모든 작업자들이 데이터베이스에서 데이터를 어떻게 읽고 쓰는지를 인식하고 있다. 활성화 레코드 패턴 패턴은 언제 사용하는가? 활동 레코드는 생성, 읽기, 수정, 삭제와 같이 너무 복잡하지 않은 도메인 로직에서 좋은 선택이다. 단일 레코.. 더보기 [SA강좌] Part 4-11 Row Data Gateway패턴 행 데이터 게이트웨이(Row Data Gateway) 패턴 행 데이터 게이트웨이 패턴의 정의 데이터 소스에 있는 단일 레코드를 접근하기 위한 게이트웨이 같이 행동하는 객체 행별 하나의 인스턴스가 있다. 그림 Ⅴ-14. 행 데이터 게이트웨이 패턴의 구조 행 데이터 게이트웨이 패턴의 설명 메모리 객체에 있는 내제된 데이터베이스 접근 코드는 몇몇 단점을 피할 수 있다. 작업 시작시 메모리 객체가 자신의 비즈니스 로직을 포함하고 있다면, 데이터베이스 조작 추가는 복잡성을 높이게 된다. 행 데이터 게이트웨이는 레코드 구조에 있는 레코드와 같는 객체를 제공한다. 그러나, 이러한 개체는 프로그래밍 언어의 일반적 메커니즘에 접근을 할 수 있다. 모든 데이터 자원 접근의 세부사항은 이 인터페이스 뒤에 숨게된다. 행 데이.. 더보기 [SA강좌] Part 4-10 Table Data Gateway 패턴 테이블 데이터 게이트웨이(Table Data Gateway) 패턴 테이블 데이터 게이트웨이 패턴의 정의 데이터베이스에 대한 게이트웨이와 같은 행동을 하는 개체 이다. 하나의 인스턴스가 테이블에 있는 모든 행을 조작한다. 그림 Ⅴ-13. 테이블 데이터 게이트웨이 패턴의 구조 테이블 데이터 게이트웨이 패턴의 설명 테이블 데이터 케이트웨이는 단일 테이블이나 뷰(select,insert,update,delete)를 접근하기 위한 모든 SQL을 포함한다. 또한, 다른 코드 데이터베이스와 상호작용을 하기 위한 모든 메서드를 호출한다. 테이블 데이터 게이트웨이 패턴은 언제 사용하는가? 테이블 데이터 게이트는 아주 간단한 데이터베이스 인터페이스 패턴으로 사용 할 수 있다. 이 패턴은 테이터베이스 테이블 또는 레코드형으.. 더보기 이전 1 2 3 4 5 ··· 9 다음